Early in the life of Coplay we ran into a challenge with parallel tool calls. At any given moment, Coplay has access to between 80 and 100 tools (we balance the ideal abstraction using internal benchmarks). For a typical level generation task, you could expect to call the place_object tool roughly 200 times for different objects. This results in lots of back-and-forth tool call responses and undesirable latency.
In response, we created specific workarounds such as DSLs that would allow agents to call multiple tools via code. This worked well, and when we saw the recent announcement about Codemode from Anthropic, we decided to polish up our batch tool calling approach.
What Codemode Promises
-
Token Savings — By keeping intermediate results out of the model's context, Codemode dramatically reduces token consumption. Anthropic reports a 37% reduction in token usage on complex tasks.
-
Reduced Latency — Each API round-trip normally requires model inference. By allowing the model to write code that orchestrates multiple tool calls sequentially, you eliminate many inference passes compared to making separate requests for each tool invocation.
-
Improved Accuracy — Writing explicit orchestration logic in Python produces better results than juggling multiple results through natural language processing.
Why We Needed a Different Approach
We realized we're in a unique position. We want the power of codemode—especially the ability to pass context inside scripts instead of between tool calls—but compiling C# code is slow, especially in large Unity projects.
At the same time, we need the model to be able to use C# when it's making Unity-related changes as part of the code it's executing. The code Coplay writes often includes standard Unity operations alongside our pre-defined tool calls.
The Hybrid Solution
After some research we found that the best solution in our case is a hybrid system for calling tools. Coplay agents can request to read tool definitions in either Python or C# and then execute them in the respective languages.
The model only reads the tools it needs, and it knows that if it reads a definition in Python, the same tool is available in C# and vice versa. This means:
- Context savings — We don't load all 80-100 tool definitions upfront
- Python speed — Python execution is just as fast as JSON tool calling, but with the added power of doing transformations in code
- C# power — While C# is the slowest way to call tools, it's the most powerful for Unity-specific operations
Demonstrating Unity actions being executed via Python.
Theoretical Benefits
Our default initial context size for conversations was reduced from 30K tokens to 12K tokens—a 60% reduction.
But we noticed during testing that there's an increased load on output tokens (which are more expensive) because the models tend to output more tokens in codemode. Unfortunately, tool call context tokens are extremely cheap because they are cached, which means that even a slight increase in output tokens can overshadow the 60% decrease in initial context tokens. For certain tasks, the execution of the tools via code leads to less LLM-consumed tokens between messages, which helps save on context and costs.
On our internal benchmarks, the hybrid approach decreased costs by 2% and improved task success rate by 31%. But since game creation is visual and task success can be quite subjective, the real test is how it performs in production.
Measured Results
We deployed this early in December and compared it to our historical data. We used an LLM to judge task success based on a user's responses to AI messages.
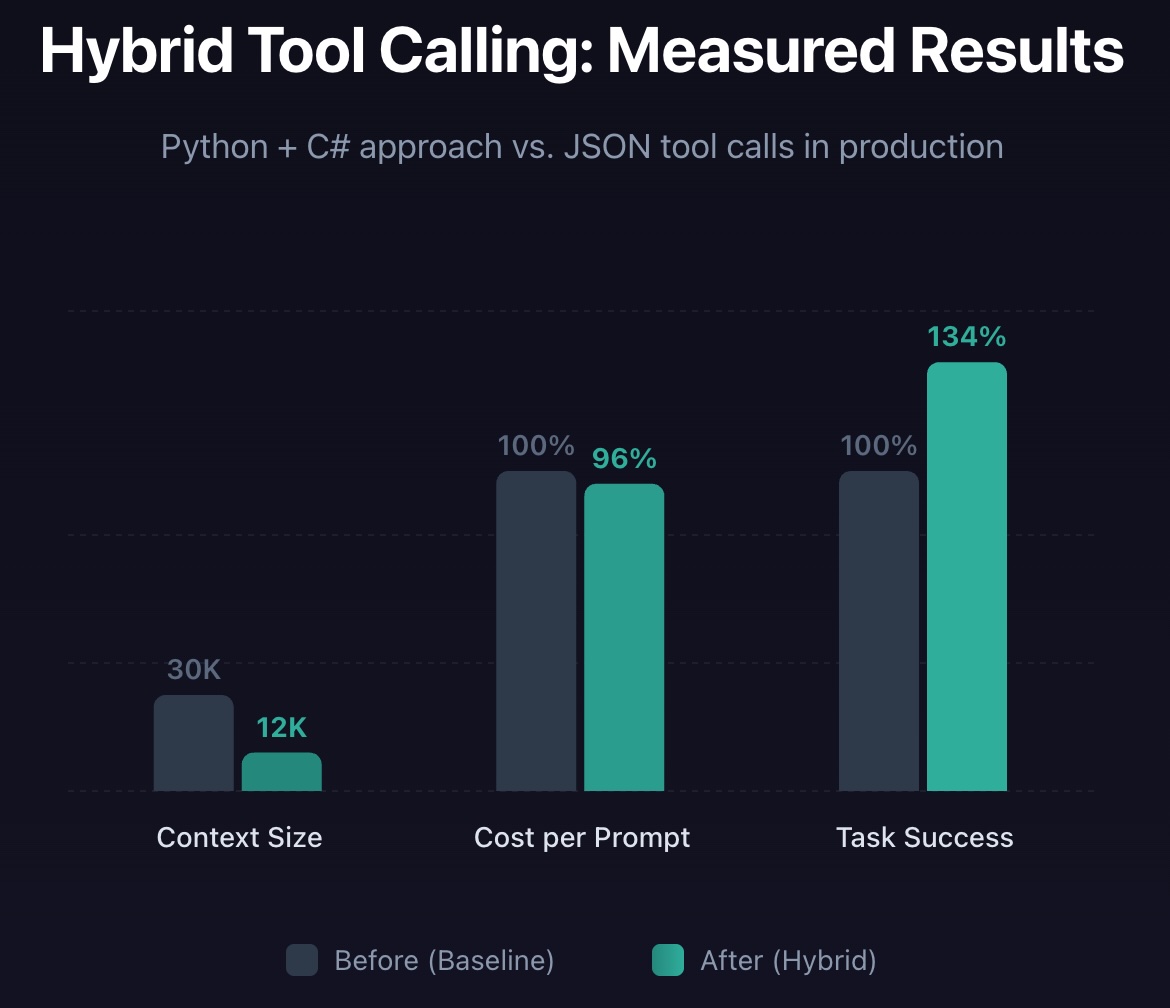
In production:
- Average cost per prompt decreased by 4% compared to the previous month
- Task success increased by 34%
Idea Graveyard
Some other things we tried that didn't work:
Simple tool defer and JSON read — Didn't work. It completely broke GPT and Gemini. Claude hallucinated assumptions about how tools should be called—it worked a bit, but not reliably.
Using a proxy tool — In this case we create a new tool, that is meant to call the deferred tools. We tried calling it "tool", but that still confused the model. Calling it "skills" worked fine for all providers. Naming matters more than you'd expect. This worked ok, but didn't yield the same accuracy as the Python-C# hybrid approach.
What's Next
We continually try to push the boundaries for our users. We've got some exciting research around extreme context savings and also ways to visually present changes that Coplay makes (think images and videos) in your pull requests.